
【成功案例】助攻 AI 數據準備:ComPDFKit 協助資料供應商,一週內完成數百萬份 PDF 數據結構化
自從 ChatGPT 問世以來,開發人員已廣泛採用 RAG(檢索增強生成)技術,將知識庫整合到 LLM(大型語言模型)中,以提升模型性能,且無需針對每個特定任務重新訓練模型。這種方法結合了 LLM 的推理能力與外部知識,顯著提高了生成結果的準確性。因此,要訓練高品質的 AI 模型,知識庫不僅需要包含豐富的資料,更要確保資料品質。在這種情況下,資料供應商(Data Providers)扮演了至關重要的角色。
然而,由於 PDF 格式屬於非結構化資料的特性,其中的內容無法直接用於 AI 訓練。因此,資料供應商過去投入了大量人力進行手動提取和處理這些非結構化資料,這不僅耗時且容易出錯。
為了應對這個挑戰,一家頂尖的資料供應商尋求 ComPDFKit 的協助,期望透過我們強大的資料擷取(Data Extraction)能力,高效可靠地將大量的 PDF 文件結構化。
ComPDFKit 根據他們的要求,量身打造了一個結合 AI 與多種演算法的模型。我們僅用 5 天就處理了超過 300 萬份 PDF 文件,提供了高品質的結構化資料。不僅減輕了客戶的人工處理負擔,也顯著提升了他們終端客戶 AI 模型訓練的效率與有效性,進而協助供應商及其客戶擴展業務營運。
客戶的資料需求
在這競爭激烈的華人數據市場中,這家供應商擁有最大規模且高品質的真實數據資料庫。隨著 AI 技術快速發展,越來越多客戶尋求他們的資料來優化 AI 模型的訓練。然而,客戶回饋指出,透過人工處理的 PDF 資料品質參差不齊,導致 AI 模型性能不如預期。
他們深知 ComPDFKit 在 PDF 資料擷取服務方面以快速、精準和高品質著稱,因此尋求我們的協助,處理超過 300 萬份 PDF 文件。
根據業界標準,ComPDFKit 的資料擷取通常可確保單一文件 80% 的準確度,能夠準確識別文字、表格、圖像、頁首、頁尾等元素,這已符合大多數企業的資料偵測標準。然而,考量到 AI 模型訓練的特殊性,即使文件內有 20% 的微小錯誤數據 (Dirty Data) ,仍嚴重影響模型準確性。
因此,該供應商提出了特定的要求:
- 對多欄位或不規則的版面配置,進行區段化識別並按順序記錄。
- 移除文件中的頁首、頁尾、頁碼和頁邊標題等不必要的元素。
為滿足這些需求,ComPDFKit 專門的研發團隊客製化資料擷取參數,使其精確對齊客戶的要求,確保超過 300 萬份文件中,有 80% 的 PDF 能完全符合他們的高標準要求。
我們克服了哪些技術挑戰?
ComPDFKit 的 OCR (光學字元辨識) 功能已能準確地從 PDF 文件中提取純文字。然而,要進一步辨識不同格式、版面配置和字體的文字,以及準確識別圖像、圖表、表格等內容,才是資料提取關鍵且充滿挑戰的環節。面對資料供應商數量龐大、類型複雜且跨越多個行業的 PDF 文件,ComPDFKit 遇到了以下幾項重大的技術挑戰。
表格處理的挑戰 (Challenges in Tables)
在 PDF 文件中,辨識並從表格中擷取資料是一個艱鉅的挑戰。許多行業的報告和文獻通常包含多層巢狀、合併儲存格、不同字體和邊框樣式的複雜表格。表格結構的這些複雜性使得要準確擷取並格式化資料的難度大大增加。
對於典型的複雜表格,一般的表格辨識效果往往缺乏精準度且邏輯關係混亂。使用這類資料進行 AI 分析容易導致不準確的結果。
圖表與影像處理的挑戰 (Challenges in Charts and Images)
大多數行業的研究報告、專案文件和學術論文等,都會包含各種圖像和圖表(例如線圖、長條圖、圓餅圖)。這些圖表中的「髒數據」,包括圖例、標籤、座標軸數值、標題和註腳等,往往會影響 AI 模型訓練的有效性。
模組區分識別的挑戰 (Challenges in Module Distinction)
PDF 文件通常包含文字、圖表和影像等多元內容,導致版面配置不規則。例如,文字可能與圖表緊密交織,或影像和表格在排列上相互交叉。這種多樣性對於準確區分文件模組帶來了巨大挑戰。傳統演算法往往無法有效處理如此複雜的版面結構,導致內容排版混亂。
舉例來說,傳統 OCR 演算法是逐行、從左到右辨識內容,而沒有進行版面分析來區分模組。結果是,擷取的資料缺乏連貫性和邏輯性,可能導致 AI 進一步分析時產生不準確的結果。
段落處理的挑戰 (Challenges in Paragraph Processing)
段落處理與模組區分密切相關。在準確分析和辨識 PDF 文件的版面配置之後,即使文件的整體結構可以保持與原始文件一致,每個模組的文字仍然是逐行提取的,將每一行視為一個獨立的段落。這種資料擷取方法限制了 AI 理解內容的能力,因為它未能捕捉段落之間的邏輯關係和語義連貫性。
有效的段落處理應包括準確識別段落邊界和在段落層級進行語義分析,以便更好地理解和利用文件中的資訊。
(備註: 傳統演算法是逐行斷開;ComPDFKit 模型則以段落為單位提取,保留了完整的語義結構。)

使用 ComPDFKit 帶來的實際成效
為了應對 PDF 資料擷取中的複雜性和準確性挑戰,ComPDFKit 針對圖像、圖表、表格、版面配置和段落處理,客製化了一個 AI 模型,以高效解析和擷取 PDF 文件資料。在此基礎上,我們根據客戶的回饋,調整了資料偵測參數,清理了不符合標準的資料,確保品質達到極高標準。
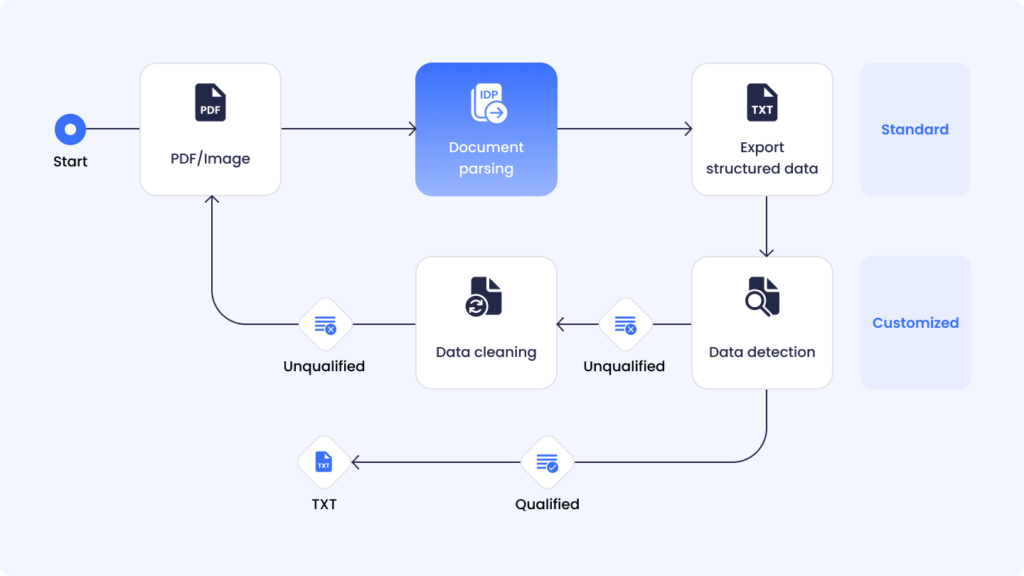
透過持續優化,我們成功在 5 天內處理了超過 300 萬份 PDF 文件,資料合規率達到 88%,完全符合客戶的嚴格要求,並協助他們訓練出更精準的 AI 模型!
未來合作展望
ComPDFKit 的高品質數據處理服務以及專業及時的技術支援,吸引了這家資料供應商尋求進一步的合作。他們計畫整合 ComPDFKit PDF SDK,以便能獨立地從 PDF 文件中擷取資料。未來,他們更打算整合 ComIDP 解決方案來處理非 PDF 的其他非結構化資料,從而擴大業務範疇,為其客戶提供更多、更高品質的資料。如果您也面臨海量資料處理的挑戰,想節省人力成本、提升資料品質和工作效率,歡迎隨時聯繫我們,一起討論更多數據應用的可能性!
Connect with KDAN
Follow us to receive all latest updates and promotions.