如何利用OCR转档工具提取扫描档或图档内的文字信息?
KDAN PDF Reader 整合光学文字识别(OCR)技术,可识别图档和扫描PDF文档中的文字信息,并将它们转换为可搜寻内文和编辑的PDF。
利用光学文字辨识(OCR)工具进行PDF转档
透过 OCR 工具,你无须再重新设定排版格式或重新建立文档,KDAN PDF Reader 直接帮你从图档和扫描档内提取文字信息。你可以先扫描如杂志、期刊或海报等纸本印刷书籍,并配合 OCR 文字识别工具将扫描档转为可编辑的档案,你可接续运用在报告、论文或作业内容中。下列将带你了解 KDAN PDF Reader 如何使用 OCR 技术将扫描档转换为可编辑的PDF。
免费试用我们的OCR PDF工具。
如何使用 OCR 工具提取扫描文件中的文字?
通过 OCR(光学字符识别)技术,你可以将扫描的 PDF 或图片中的文字转换为可搜索、可编辑的数字内容。KDAN PDF Reader 集成 OCR 功能,让你无需重新输入或排版,就能快速提取纸本文字。
OCR 如何帮助你转换扫描 PDF?
- 自动识别扫描文件或图像中的文字,转为可编辑的 PDF
- 保留原有版式,无需重做文件
- 适用于杂志、期刊、收据、海报等纸质扫描内容
- 你只需扫描纸质文件,使用 KDAN PDF Reader 打开并启用 OCR 功能,即可轻松将图像文字转为可复制、可搜索、可再次利用的文本。
让扫描文件变得可搜索、可复制
一般扫描的 PDF 无法搜索或复制内容,使用 OCR 可解锁这些“冻结”的信息,使重要内容可检索、可重用,提升报告整理、资料比对或引用的效率。
如何在 Mac 上利用 OCR 识别文字并转为可搜寻内文的 PDF 文档
KDAN PDF Reader 中的 OCR 文字识别功能帮你轻松辨识图档内的文字信息。您只需要汇入欲套用 OCR 转档工具的档案,KDAN PDF Reader 便可帮你处理后续所有步骤。
从扫描文档中提取文本:
1. 打开扫描的 PDF 文档并点击上方选项的"OCR"。
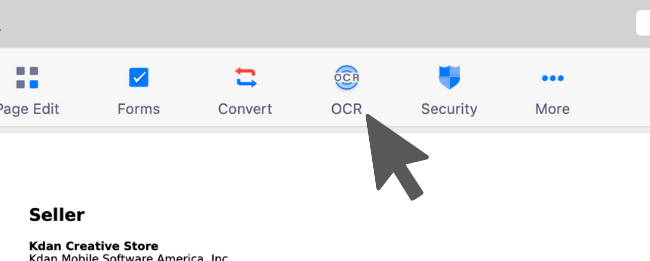
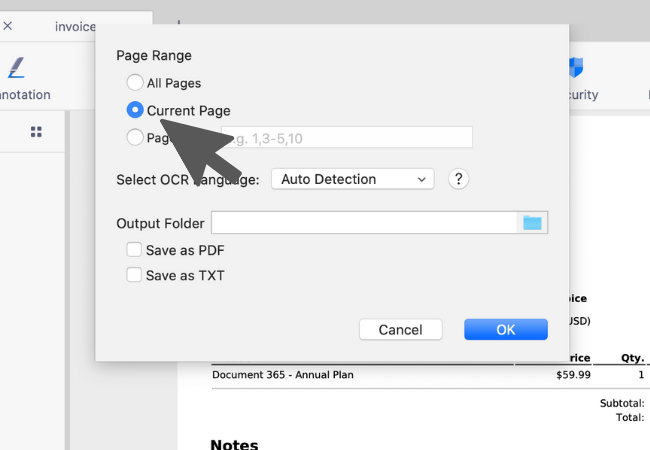
2. 选择欲执行OCR文字识别的页面范围。
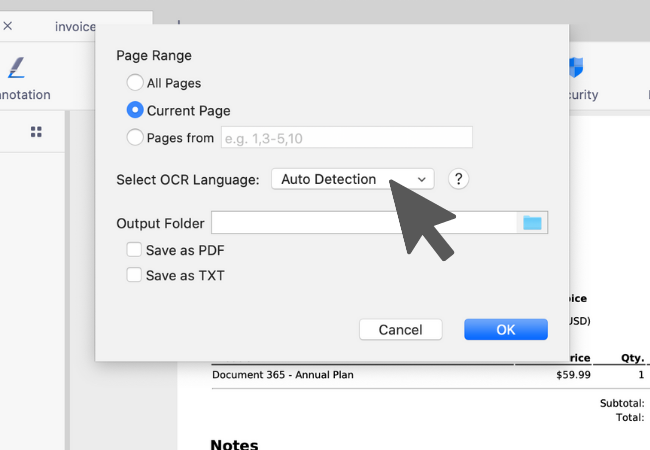
3. 您可以选择由 KDAN PDF Reader 自动侦测文档内容的语言,或手动设定符合该文件所运用的文字语言。
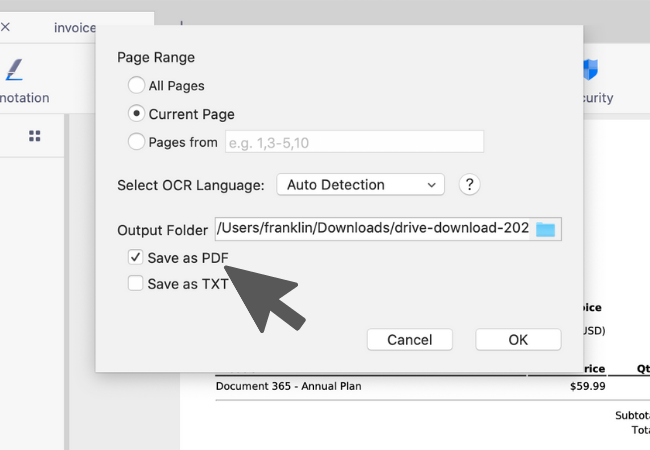
4. 设定一目标资料夹存放转出后的档案,再选择要以可搜寻内文的PDF或是以纯文字格式汇出。
5. 点击"确认(OK)"后,KDAN PDF Reader 将开始进行 OCR 转档。
从图档中提取文本:
1. 进入"首页"分页后,再点击"图档转PDF"的快捷入口。
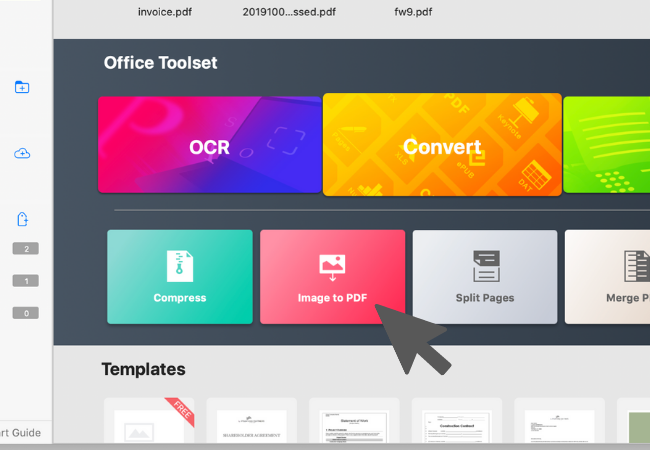
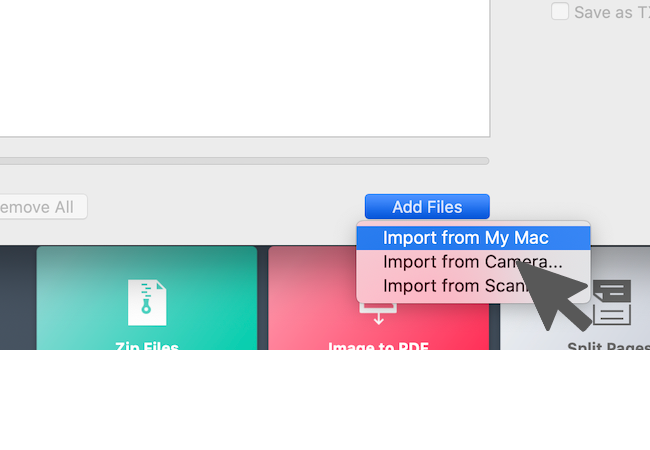
2. 点击"新增档案"按钮后,您可以选择从 Mac 的 Finder、相机或已连结的扫描器汇入图片。
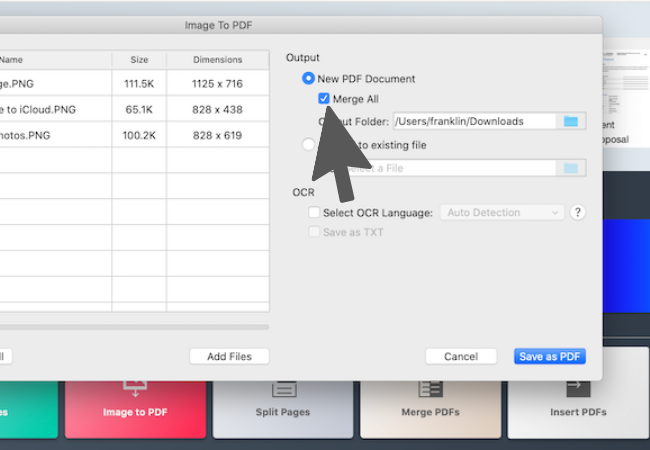
3. 汇入图像后,您可以在输出设定中勾选"合并全部(Merge All)"的选项,可将所有汇入的图档合并成单一 PDF。同时,您也可以选择直接将汇入的图档直接添加到现有的PDF中。
4. 欲执行 OCR,只需点击启用 OCR 的选项并设定图档内本文的语言。
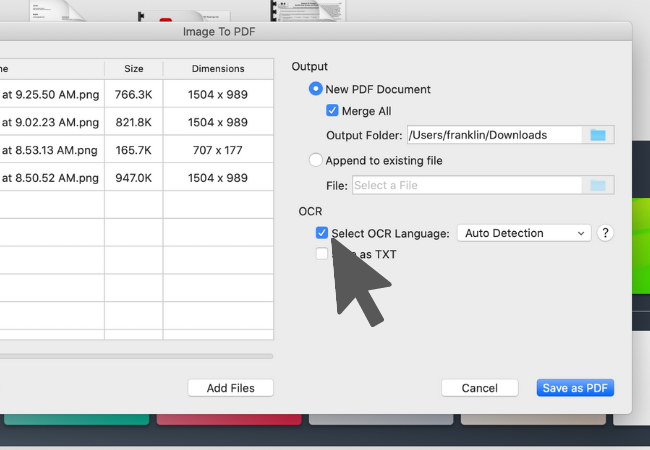
5. 点击「另存为PDF(Save as PDF)」按钮,KDAN PDF Reader 便会执行 OCR 转档将图像转为可搜寻文字内容的PDF。
立即试用看看KDAN PDF Reader —— 无论是 Windows、Mac、iOS 或 Android 平台,都能使用,解锁 PDF 的全部功能!
OCR 的应用实例带你了解运作方式
OCR 的功能用途主要将纸本印刷档案转为可搜寻且编辑文本的文档。当利用 OCR 转档方式将扫描图档转换为可编辑的档案,可进一步再使用 Microsoft Office 和 Google Docs 等服务做进一步内容编辑。
省去耗时的人工步骤
无论再怎么有经验的人,手动输入资料数据偶尔还是会有出错的机率。如果仅是一个小错误,可能无伤大雅。但若错误的次数和数量过多话,除了让人容易感到沮丧外,还有可能不小心引起财务上的损失。 KDAN PDF Reader 搭配 OCR 的技术应用,帮你轻松创建可搜寻及编辑文本信息的文档,可减少重新建立档案时的人为失误!
让纸本转为可搜寻本文的档案
印刷纸本和经过扫描产生的档案多无法搜寻本文或编辑,涵盖大量的冻结且无法使用的文字信息,也因此让读者很难有效地找到特定的字辞或重要资讯。透过 OCR 转档工具,这些倍冻结的文本内容皆可转为可被读取、搜寻的信息,帮你更有效捕捉到档案内的核心内容,而这些文本信息是可以被复制且贴至其他用途上。
在无纸化生活中仍条理分明
尽管许多企业单位都已逐步将收据档案转为数位化格式,但你仍有可能在销售交易中收到纸本收据。若能将纸本收据扫描并以电子档案进行保存,仍不失为一个聪明的作法。尤其, 一般组织单位内要进行核销作业时仍需要提交收据资料,你可以利用 OCR 转档工具提取出收据内的文字信息,让你从过往的收据资料中,找到重要资讯或是用来申请保修维护的依据。

KDAN PDF Reader 免费版和订阅版有何区别?
免费版可用于查看与批注 PDF。升级至 Document 365 后,您可以使用密码保护、分割合并页面、PDF 转档、OCR 图像转文字等高级功能。若需要 AI 功能,可选择 Document 365 AI+ 方案,解锁 AI PDF 工具。
KDAN PDF Reader 支持哪些设备与平台?
支持 Windows、Mac、iOS、Android 平台。订阅 Document 365 后,可实现跨平台同步,随时无缝切换设备。
KDAN PDF Reader 支持哪些语言?
支持 英语、繁体中文、简体中文、日语、意大利语、法语、德语、西班牙语、葡萄牙语、韩语和俄语。
如何升级到高级功能或订阅方案?
您可以通过 KDAN Creative Store,或在 App Store、Google Play、Microsoft Store 升级订阅。
遇到问题时如何联系客户服务?
您可先访问 KDAN Support Center 查看常见问题。如遇到账号或内购问题,请发送邮件至 helpdesk@kdanmobile.com。
我们如何保护您的数据安全?
KDAN PDF Reader 符合 GDPR 规范,并遵循国际安全标准。详情请参阅我们的 隐私政策。
关注 KDAN
关注 KDAN 官方微博,了解最新产品资讯。