How to Convert Scanned PDF Documents to Text with OCR?
KDAN PDF Reader enables you to extract text content from images and scanned PDFs and turn them into searchable and editable PDF files using optical character recognition (OCR).
PDF Conversion with Optical Character Recognition (OCR)
With OCR, you can extract text content from scanned documents without re-creating and re-formatting them. You can scan printed or paper documents, such as magazines, journals, posters, and more, and convert them into editable PDFs or text files for further editing in essays, reports, or homework assignments. Learn how KDAN PDF Reader uses OCR technology to convert your scanned files into editable PDF files.
Try our OCR PDF tool for free.
How to Use OCR to Extract Text from Scanned PDFs?
With OCR (Optical Character Recognition), you can convert scanned PDFs or images into searchable and editable digital text. KDAN PDF Reader integrates OCR technology, allowing you to extract text from printed documents without retyping or reformatting.
How Does OCR Help Convert Scanned PDFs?
- Recognizes text directly from scanned documents or images and converts them into editable PDFs
- Preserves the original layout—no need to recreate the document
- Works with magazines, journals, receipts, posters, and other scanned paper materials
Just scan your paper document, open it in KDAN PDF Reader, and enable the OCR feature to convert static images into selectable, searchable, and reusable text.
Make Scanned PDFs Searchable and Copyable
Scanned PDFs are usually non-searchable and can’t be copied. With OCR, you can unlock that "frozen" text, making it searchable and reusable—great for organizing reports, comparing data, or quoting content efficiently.
How To Recognize Text with OCR and Convert to Searchable PDF Documents on Mac
The OCR functionality in KDAN PDF Reader makes text recognition as simple as possible. Choose the file you want to apply OCR for, and KDAN PDF Reader will handle the rest.
OCR Scanned Documents:
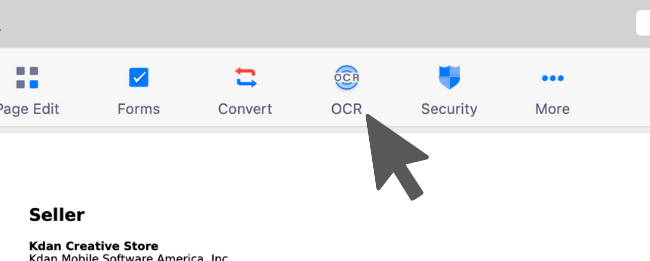
1. Open the PDF and click "OCR" from the top menu.
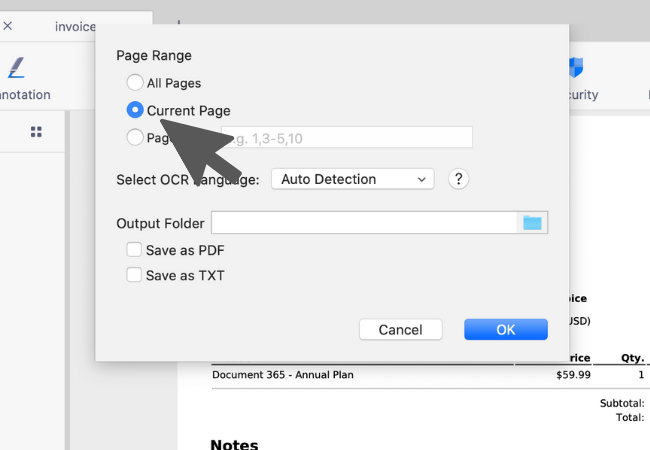
2. Select a page range where you woul like to apply OCR.
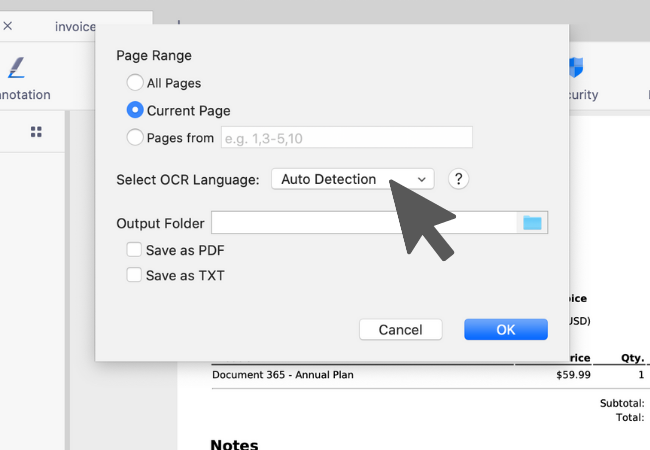
3. You can set KDAN PDF Reader to automatically detect the language of a document, or you can manually select a language for the document.
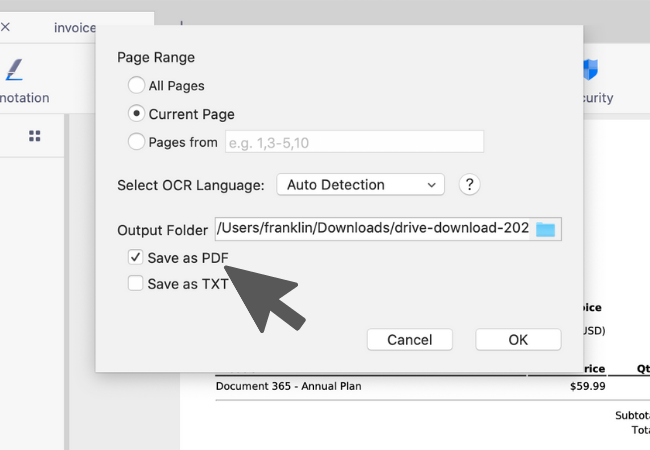
4. Select a destination folder for the output. Then you could choose searchable PDF or plain text as the output format.
5. Click "OK", and KDAN PDF Reader will process the OCR conversion.
OCR Images:
1. Go to the "Home" tab and select "Image to PDF".
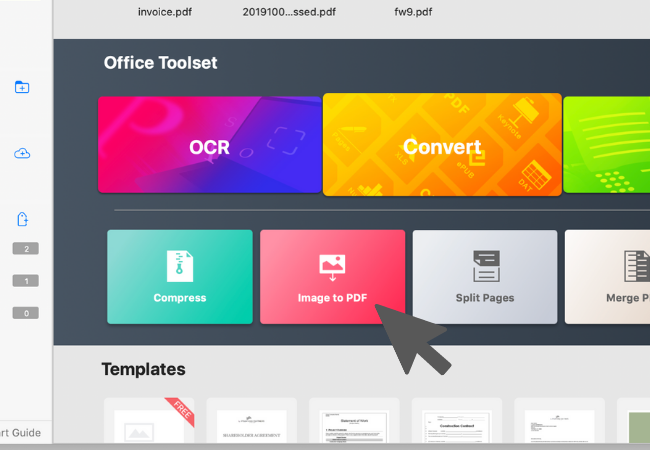
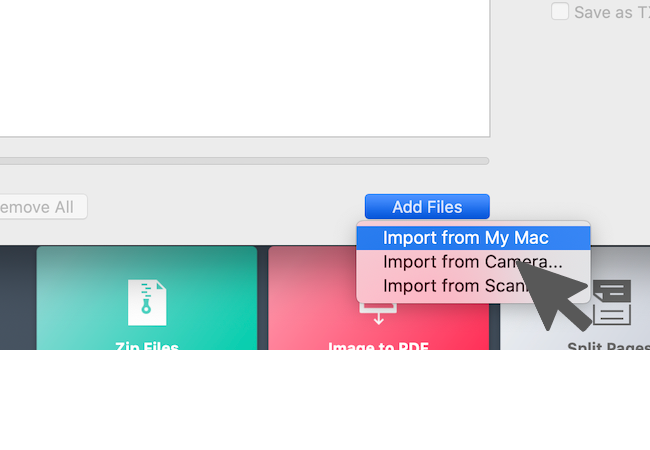
2. You can import images from Mac Finder, camera, and scanner by clicking "Add Files".
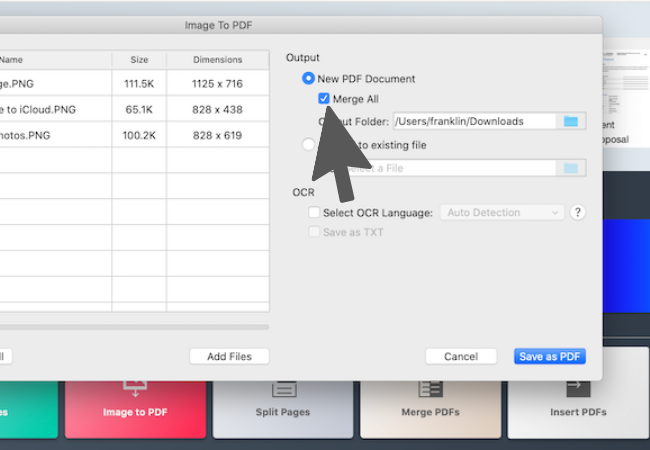
3. After you've imported images, you can toggle the "Merge All" option in the Output section to combine all images into one PDF. Alternatively, you can directly add the output file to the existing PDF.
4. To perform OCR, simply toggle the OCR option to choose the language for the images.
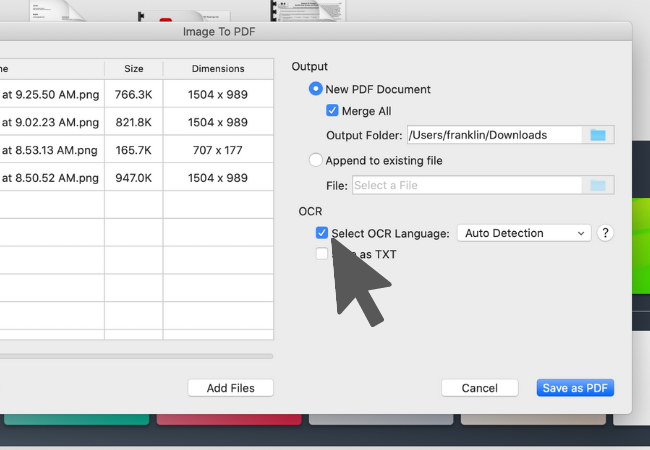
5. Click "Save as PDF", and KDAN PDF Reader will convert the images to searchable PDFs with OCR.
Try KDAN PDF Reader now — available on Windows, Mac, iOS, and Android platforms. Unlock all PDF features!
How does OCR Work? Examples of How It is Used
OCR is typically used to create selectable and editable text files from printed documents. Once scanned paper documents are converted to digits with OCR, the text can then be edited with word-processing software like Microsoft Office and Google Docs.
Eliminate Manual Work
No matter how well-trained you are, manual data entry is always prone to errors. When you make only one mistake, it will not cause a big problem. However, if you make several mistakes, you will be frustrated and, worse yet: you will lose money. Using OCR technology, you can create searchable and editable text files that eliminate human error when composing documents from scratch.
Make Immutable Files Searchable
Printed documents and textual electronic images contain information that cannot be searched or edited. This means they contain a lot of frozen information. The problem is that it's difficult for you to find a specific phrase, word, or piece of vital information efficietly. By using OCR technology, you can convert that frozen text into machine-readable data that can be searched. You can then find and capture the essential information in the documents, which can be copied and pasted for other purposes.
Stay Organized in a Paperless Life
Despite the fact that many places have digitized the receipt process, you may still receive a printed receipt in a sales transaction. It's a good idea to digitize these receipts, so they can be preserved. Some employers even ask for receipts when they process expense reports. The OCR tool will help you quickly view old receipts to carry out your taxes or claim warranty claims.
Your Best Adobe Acrobat Alternative
With KDAN PDF Reader, you can already do anything you need with PDFs. Create, Edit and Share PDFs all in one convenient app.

What are the differences between the free and subscription versions of KDAN PDF Reader?
The free version of KDAN PDF Reader lets you view and annotate PDFs. By upgrading to Document 365, you can access advanced features such as password protection, split and merge pages, file conversion, and OCR. For AI-powered functions, subscribe to Document 365 AI+ to unlock AI PDF tools.
Which devices and platforms does KDAN PDF Reader support?
KDAN PDF Reader is available on Windows, Mac, iOS, and Android. With a Document 365 subscription, you can work seamlessly across devices with cross-platform access.
Which languages does KDAN PDF Reader support?
The app supports English, Traditional Chinese, Simplified Chinese, Japanese, Italian, French, German, Spanish, Portuguese, Korean, and Russian.
How can I upgrade to advanced features or a subscription plan?
You can upgrade through the KDAN Creative Store or via major app stores such as App Store, Google Play, and Microsoft Store.
How can I contact customer support if I encounter issues?
Check the KDAN Support Center for FAQs and guides. For account or in-app purchase issues, email helpdesk@kdanmobile.com.
How does KDAN protect my data?
KDAN PDF Reader complies with GDPR regulations and follows international security standards. Please refer to our Privacy Policy for details.
Need Help?
Visit our support center or reach out to our support team at helpdesk@kdanmobile.com.
Connect with KDAN
Follow us to receive all latest updates and promotions.